
Received date: 2024-04-22
Online published: 2025-05-09
Copyright
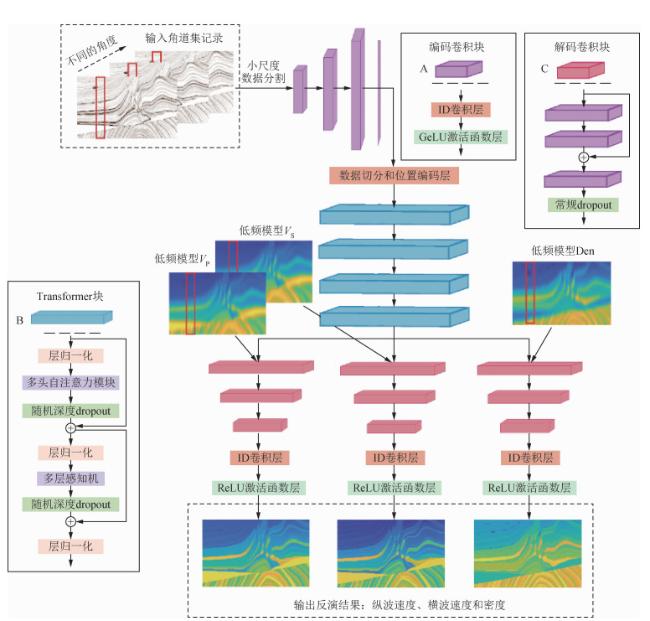
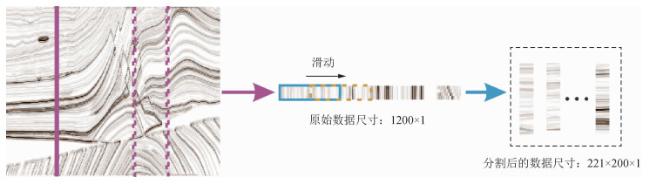
Pre-stack AVO inversion is one of the key methods for reservoir characterization, from which abundant elastic parameters in underground media can be obtained, which is conducive to the identification of oil and gas reservoirs. The inverse problem of pre-stack angular track set recording to elastic parameters is challenging in terms of adaptability and resolution. To solve these problems, a pre-stack AVO inversion network based on Transformer framework is proposed in this paper to solve the velocity and density of P-S wave. Inversion results are unstable and transverse continuity is poor in the network that uses pre-stack seismic data as one-way input. Therefore, prior knowledge constraints are introduced in training to improve the stability and accuracy of inversion results. In order to reduce the dependence on well data inversion, this paper uses transfer learning strategy to transfer the trained model to the real data inversion. In the data preprocessing stage, the data augmentation method is used to expand the training samples, so that the proposed network can fully extract the pre-stack trace set information, and establish the complex nonlinear mapping relationship between the pre-stack trace set and the elastic parameters. In this paper, the method of multi-task learning is used to realize simultaneous inversion of P-wave velocity, S-wave velocity and density, so as to improve the inversion accuracy and calculation efficiency. Through inversion testing of Marmousi2 synthetic data and actual data, and comparing with classical deep learning frameworks, the multi-task Transformer framework proposed in this paper has higher accuracy and high-resolution inversion results.
Key words: Pre-stack AVO inversion; Multi-task learning; Deep learning; Transformer
LiuQing YANG , ShouDong WANG , JingMing LI . Few-shot pre-stack AVO inversion using a multi-task Transformer[J]. Progress in Geophysics, 2025 , 40(2) : 743 -757 . DOI: 10.6038/pg2025HH0544
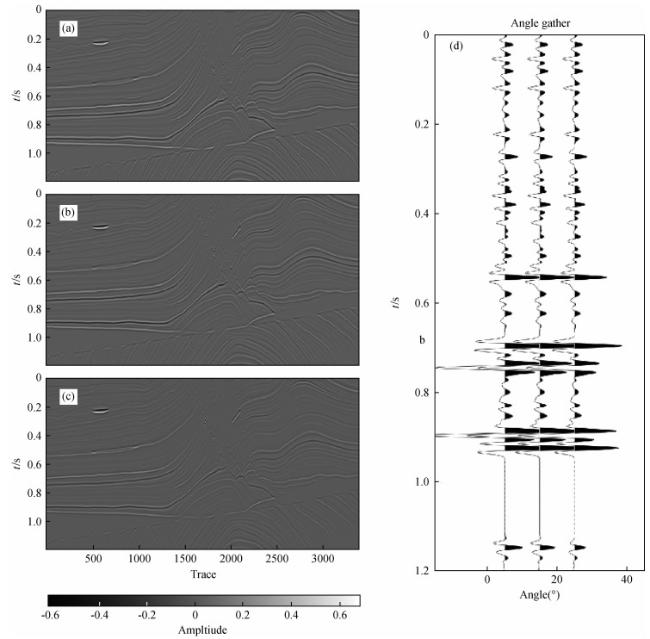
图3 Marmousi2模型合成叠前角道集记录(a)5°;(b)15°;(c)25°;(d)三个角度的角道集展示. Fig 3 Synthetic angle gathers of Marmousi2 model (a)5°; (b)15°; (c)25°; (d) The wiggle display of three angle gathers. |
图5 三个网络在合成数据中的反演结果(第700道)对比(a) 第700道的角道集展示;(b) 纵波速度;(c) 横波速度;(d) 密度. 其中黑色、蓝色、粉红色、绿色和红色线条分别表示真实值、初始先验值、CINet、不含先验模型的InvTransformer和InvTransformer. Fig 5 The comparison results of the three networks in the synthetic data (trace 700) (a) The wiggle display of three angle gathers at trace 700; (b) P-wave velocity; (c) S-wave velocity; (d) Density. The black, blue, pink, green and red lines represent the true value, the initial prior value, CINet, InvTransformer without initial prior value, and InvTransformer respectively. |
表1 不同网络在Marmoisi2合成数据中的反演结果(无噪合成数据)Table 1 Inversion results of different networks in Marmoisi2 synthetic data (noise-free synthesis data) |
| VP/(m/s) | VS/(m/s) | ρ/(g/cm3) | ||
|---|---|---|---|---|
| CINet | R | 0.9901 | 0.9937 | 0.9323 |
| RMSE | 113.15848 | 72.8784 | 0.0585 | |
| InvTransformer-seimic | R | 0.9844 | 0.9846 | 0.9442 |
| RMSE | 156.3122 | 121.4257 | 0.0587 | |
| InvTransformer | R | 0.9974 | 0.9974 | 0.9858 |
| RMSE | 60.8379 | 47.3763 | 0.0304 |
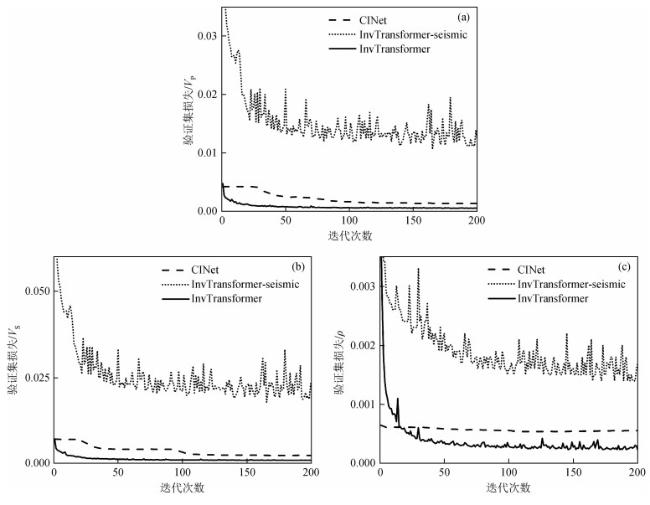
图6 不同网络训练过程中的验证集损失变化(a) 纵波速度;(b) 纵波横波;(c) 密度. Fig 6 Validation loss changes in different network training processes (a) P-wave velocity; (b) S-wave velocity; (c) Density. |
图7 三个网络在SNR=10 dB的合成数据中的反演结果对比(a) 纵波速度;(b) 横波速度;(c) 密度.每个子图从左到右分别为CINet、不含先验模型的InvTransformer和InvTransformer. Fig 7 The inversion results of the three networks in the synthetic data with SNR=10 dB (a) P-wave velocity; (b) S-wave velocity; (c) Density. Each subfigure is CINet, InvTransformer without prior model and InvTransformer from left to right. |
表2 不同网络在Marmoisi2合成数据中的反演结果(SNR=10 dB)Table 2 Inversion results of different networks in Marmoisi2 synthesis data (SNR=10 dB) |
| VP/(m/s) | VS/(m/s) | ρ/(g/cm3) | ||
|---|---|---|---|---|
| CINet | R | 0.9888 | 0.9883 | 0.9386 |
| RMSE | 124.6051 | 102.1162 | 0.0556 | |
| InvTransformer-seimic | R | 0.9218 | 0.9201 | 0.8697 |
| RMSE | 357.9108 | 280.2331 | 0.0836 | |
| InvTransformer | R | 0.9956 | 0.9949 | 0.9789 |
| RMSE | 81.1322 | 67.3704 | 0.0409 |
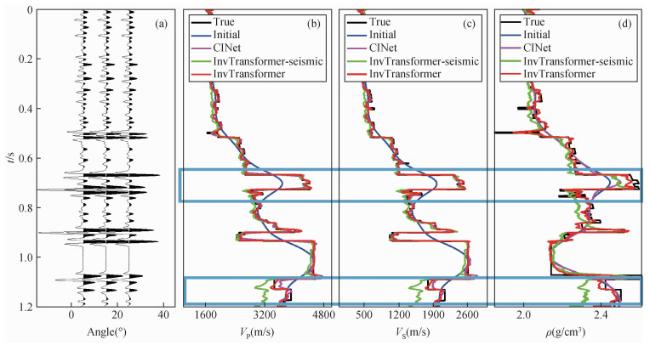
图8 三个网络在SNR=5 dB的合成数据中的反演结果(第1800道)对比(a)第1800道的角道集展示;(b)纵波速度;(c)横波速度;(d)密度.其中黑色、蓝色、粉红色、绿色和红色线条分别表示真实值、初始先验值、CINet、不含先验模型的InvTransformer和InvTransformer. Fig 8 The comparison results of the three networks in the synthetic data with SNR=5 dB(trace 1800) (a) The wiggle display of three angle gathers at trace 1800; (b) P-wave velocity; (c) S-wave velocity; (d) Density. The black, blue, pink, green and red lines represent the true value, the initial prior value, CINet, InvTransformer without initial prior value, and InvTransformer respectively. |
表3 不同网络在Marmoisi2合成数据中的反演结果(SNR=5 dB)Table 3 Inversion results of different networks in Marmoisi2 synthesis data (SNR=5 dB) |
| VP/(m/s) | VS/(m/s) | ρ/(g/cm3) | ||
|---|---|---|---|---|
| CINet | R | 0.9860 | 0.98464 | 0.9257 |
| RMSE | 140.2366 | 116.1876 | 0.05870 | |
| InvTransformer-seimic | R | 0.8862 | 0.8843 | 0.8311 |
| RMSE | 419.3198 | 325.9141 | 0.0933 | |
| InvTransformer | R | 0.9934 | 0.9926 | 0.9693 |
| RMSE | 98.1886 | 81.339 | 0.0417 |
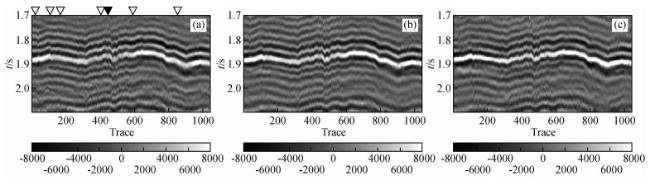
图9 实际叠前角道集叠加记录(a) 0°~10°的倾角叠加;(b) 10°~20°的倾角叠加;(c)20°~30°的倾角叠加. Fig 9 Field stacked angle gathers (a) Angle stacks of 0°~10°; (b) Angle stacks of 10°~20°; (c) Angle stacks of 20°~30°. |
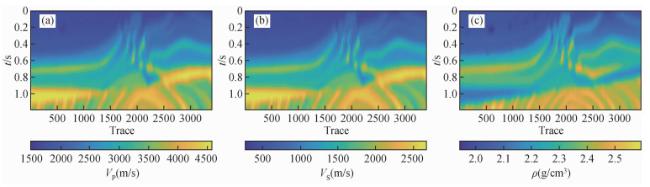
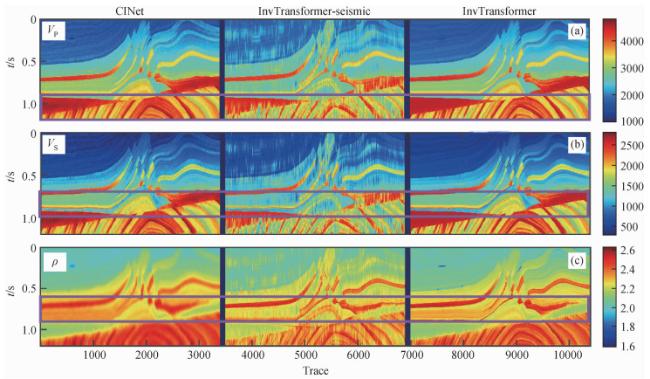
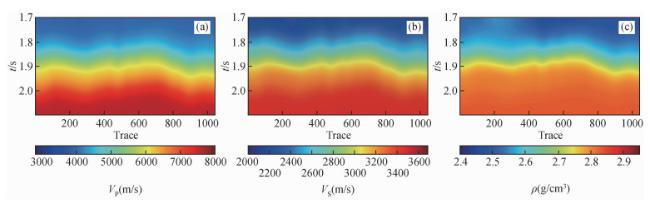
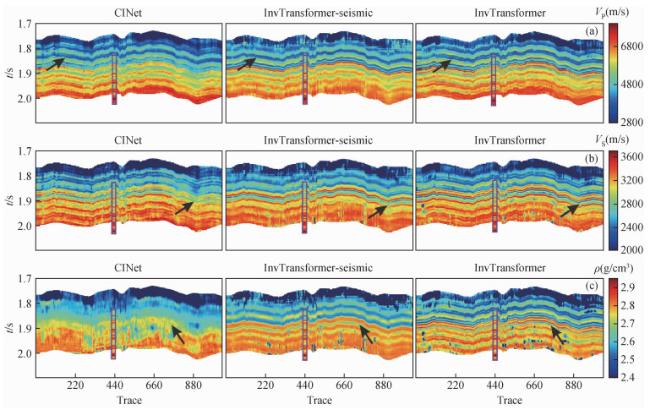
图11 三个网络在实际数据中的反演结果对比(a) 纵波速度;(b) 横波速度;(c) 密度. 每个子图从左到右分别为CINet、不含先验模型的InvTransformer和InvTransformer. Fig 11 The inversion results of the three networks in the field data (a) P-wave velocity; (b) S-wave velocity; (c) Density. Each subfigure is CINet, InvTransformer without prior model and InvTransformer from left to right. |
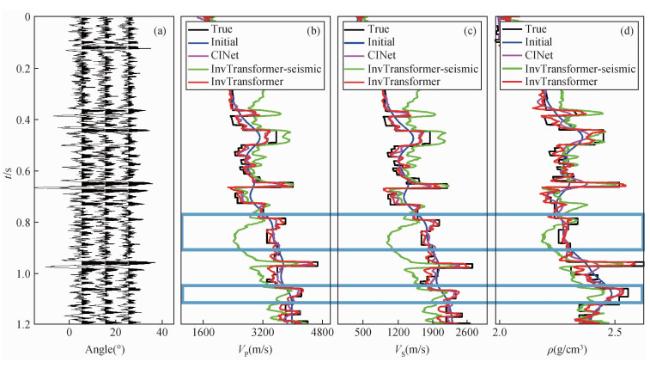
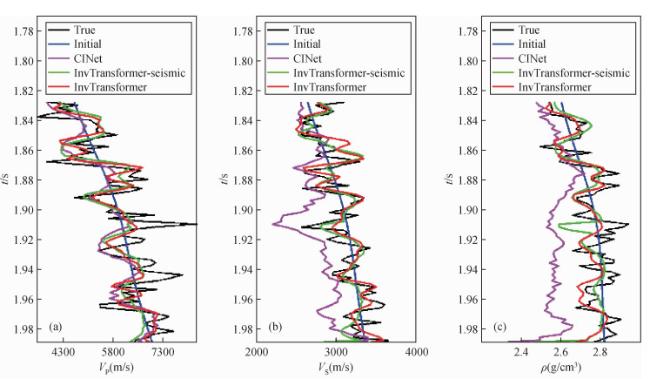
图12 三个网络在实际资料中的反演结果的盲井对比(a) 纵波速度;(b) 横波速度;(c) 密度. Fig 12 The comparison results of the three networks in the blind well of field data (a) P-wave velocity; (b) S-wave velocity; (c) Density. |
表4 不同网络在实际资料中盲井的反演精度对比Table 4 Comparison of inversion accuracy of different networks in real data of the blind well |
| VP/(m/s) | VS/(m/s) | ρ/(g/cm3) | ||
|---|---|---|---|---|
| CINet | R | 0.9028 | 0.8954 | 0.3211 |
| RMSE | 659.4684 | 371.0393 | 0.1925 | |
| InvTransformer-seimic | R | 0.8860 | 0.9258 | 0.5305 |
| RMSE | 632.1838 | 206.2297 | 0.0959 | |
| InvTransformer | R | 0.8957 | 0.9455 | 0.8087 |
| RMSE | 607.222 | 180.5329 | 0.0667 |
感谢审稿专家提出的修改意见和编辑部的大力支持!
|
Aki K, Richards P. 1980. Quantitative Seismology. San Francisco: W. H. Freeman.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Liu S K, Johns E, Davison A J. 2019. End-to-end multi-task learning with attention. //2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach: IEEE.
|
|
|
|
|
|
|
|
|
|
|
|
Wang Y M, Wang X P, Shen G Q. 2009. Pre-stack multi-angle three-parameter synchronous inversion method. //Beijing 2009 International Geophysical Conference and Exposition. Beijing, China: Society of Exploration Geophysicists.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}